
🥴ONNX 模型的修改与调试
⚠️This post is based on the official MMDeploy tutorial, with some minor modifications for clarity and context.
ONNX 的底层实现
ONNX 的存储格式
ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文件把数据存储进一份二进制文件。可以说,数据定义文件就是数据类,二进制文件就是数据类的实例。 这里给出一个 Protobuf 数据定义文件的例子:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}这段定义表示在 Person 这种数据类型中,必须包含 name、id 这两个字段,选择性包含 email 字段。根据这份定义文件,用户就可以选择一种编程语言,定义一个含有成员变量 name、id、email 的 Person 类,把这个类的某个实例用 Protobuf 存储成二进制文件;反之,用户也可以用二进制文件和对应的数据定义文件,读取出一个 Person 类的实例。
而对于 ONNX ,它的 Protobuf 数据定义文件在其开源库中,这些文件定义了神经网络中模型、节点、张量的数据类型规范;而数据定义文件对应的二进制文件就是我们熟悉的“.onnx"文件,每一个 ".onnx" 文件按照数据定义规范,存储了一个神经网络的所有相关数据。直接用 Protobuf 生成 ONNX 模型还是比较麻烦的。幸运的是,ONNX 提供了很多实用 API,我们可以在完全不了解 Protobuf 的前提下,构造和读取 ONNX 模型。
ONNX 的结构定义
在用 API 对 ONNX 模型进行操作之前,我们还需要先了解一下 ONNX 的结构定义规则,学习一下 ONNX 在 Protobuf 定义文件里是怎样描述一个神经网络的。
回想一下,神经网络本质上是一个计算图。计算图的节点是算子,边是参与运算的张量。而通过可视化 ONNX 模型,我们知道 ONNX 记录了所有算子节点的属性信息,并把参与运算的张量信息存储在算子节点的输入输出信息中。事实上,ONNX 模型的结构可以用类图大致表示如下:
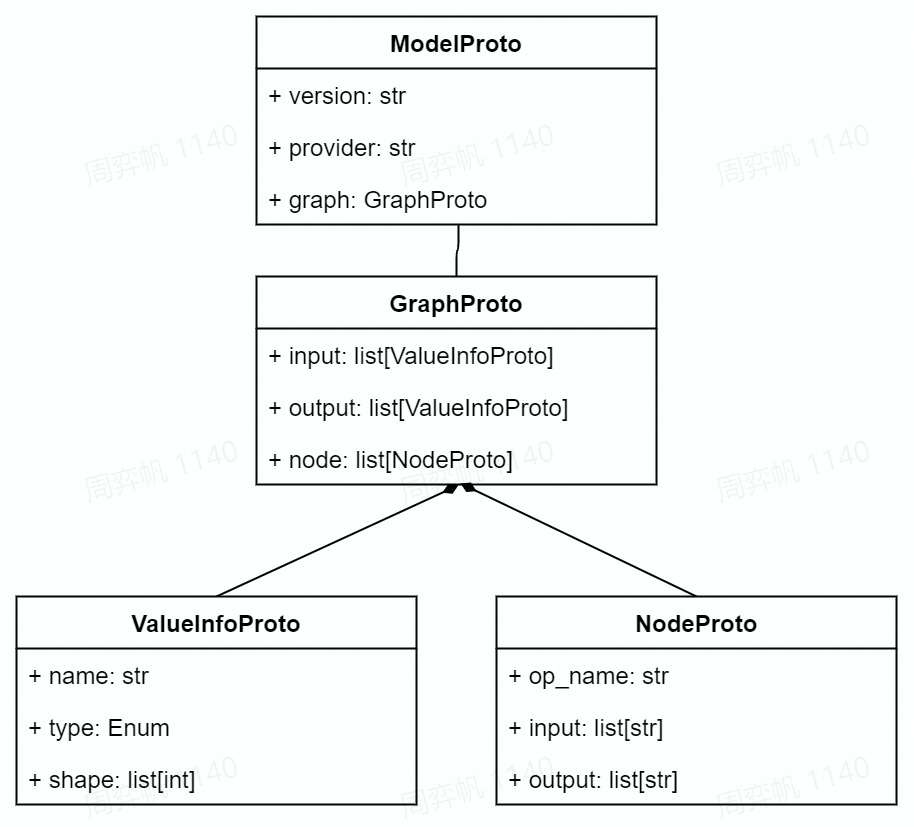
如图所示,一个 ONNX 模型可以用 ModelProto 类表示。ModelProto 包含了版本、创建者等日志信息,还包含了存储计算图结构的 graph。GraphProto 类则由输入张量信息、输出张量信息、节点信息组成。张量信息 ValueInfoProto 类包括张量名、基本数据类型、形状。节点信息 NodeProto 类包含了算子名、算子输入张量名、算子输出张量名。 让我们来看一个具体的例子。假如我们有一个描述 output=a*x+b 的 ONNX 模型 model,用 print(model) 可以输出以下内容:
对应上文中的类图,这个模型的信息由 ir_version,opset_import 等全局信息和 graph 图信息组成。而 graph 包含一个乘法节点、一个加法节点、三个输入张量 a, x, b 以及一个输出张量 output。在下一节里,我们会用 API 构造出这个模型,并输出这段结果。
读写 ONNX 模型
构造 ONNX 模型
在上一小节中,我们知道了 ONNX 模型是按以下的结构组织起来的:
ModelProto
GraphProto
NodeProto
ValueInfoProto
现在,让我们抛开 PyTorch,尝试完全用 ONNX 的 Python API 构造一个描述线性函数 output=a*x+b 的 ONNX 模型。我们将根据上面的结构,自底向上地构造这个模型。
首先,我们可以用 helper.make_tensor_value_info 构造出一个描述张量信息的 ValueInfoProto 对象。如前面的类图所示,我们要传入张量名、张量的基本数据类型、张量形状这三个信息。在 ONNX 中,不管是输入张量还是输出张量,它们的表示方式都是一样的。因此,这里我们用类似的方式为三个输入 a, x, b 和一个输出 output 构造 ValueInfoProto 对象。如下面的代码所示:
之后,我们要构造算子节点信息 NodeProto,这可以通过在 helper.make_node 中传入算子类型、输入张量名、输出张量名这三个信息来实现。我们这里先构造了描述 c=a*x 的乘法节点,再构造了 output=c+b 的加法节点。如下面的代码所示:
在计算机中,图一般是用一个节点集和一个边集表示的。而 ONNX 巧妙地把边的信息保存在了节点信息里,省去了保存边集的步骤。在 ONNX 中,如果某节点的输入名和之前某节点的输出名相同,就默认这两个节点是相连的。如上面的例子所示:Mul 节点定义了输出 c,Add 节点定义了输入 c,则 Mul 节点和 Add 节点是相连的。
正是因为有这种边的隐式定义规则,所以 ONNX 对节点的输入有一定的要求:一个节点的输入,要么是整个模型的输入,要么是之前某个节点的输出。如果我们把 a, x, b 中的某个输入节点从计算图中拿出(这个操作会在之后的代码中介绍),或者把 Mul 的输出从 c 改成 d,则最终的 ONNX 模型都是不满足标准的。
一个不满足标准的 ONNX 模型可能无法被推理引擎正确识别。ONNX 提供了 API
onnx.checker.check_model来判断一个 ONNX 模型是否满足标准。
接下来,我们用 helper.make_graph 来构造计算图 GraphProto。helper.make_graph 函数需要传入节点、图名称、输入张量信息、输出张量信息这 4 个参数。如下面的代码所示,我们把之前构造出来的 NodeProto 对象和 ValueInfoProto 对象按照顺序传入即可。
这里 make_graph 的节点参数有一个要求:计算图的节点必须以拓扑序给出。
拓扑序是与有向图的相关的数学概念。如果按拓扑序遍历所有节点的话,能保证每个节点的输入都能在之前节点的输出里找到(对于 ONNX 模型,我们把计算图的输入张量也看成“之前的输出”)。
如果对这个概念不熟也没有关系,我们以刚刚构造出来的这个计算图为研究对象,通过下图展示的两个例子来直观理解拓扑序。
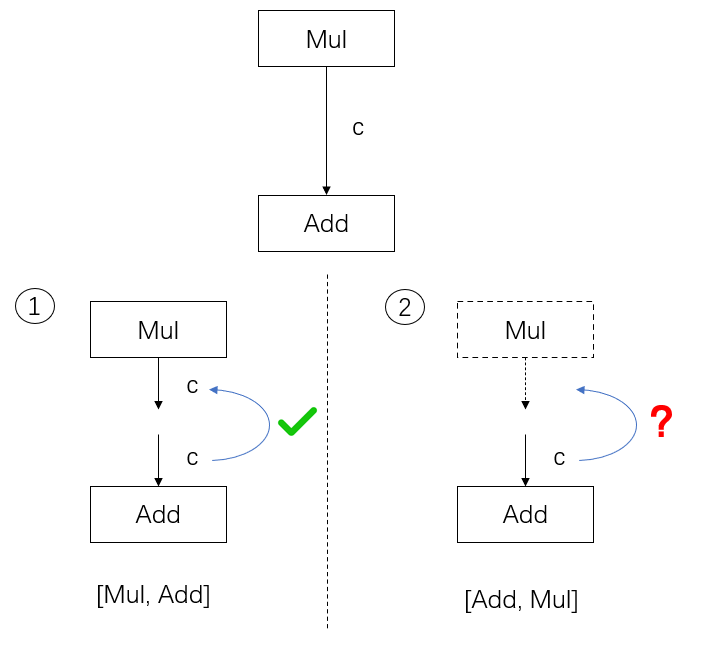
这里我们只关注 Mul 和 Add 节点以及它们之间的边 c。在情况 1 中:如果我们的节点以 [Mul, Add] 顺序给出,那么遍历到 Add 时,它的输入 c 可以在之前的 Mul 的输出中找到。但是,如情况 2 所示:如果我们的节点以 [Add, Mul] 的顺序给出,那么 Add 就找不到输入边,计算图也无法成功构造出来了。这里的 [Mul, Add] 就是符合有向图的拓扑序的,而 [Add, Mul] 则不满足。
最后,我们用 helper.make_model 把计算图 GraphProto 封装进模型 ModelProto 里,一个 ONNX 模型就构造完成了。make_model 函数中还可以添加模型制作者、版本等信息,为了简单起见,我们没有添加额外的信息。如下面的代码所示:
构造完模型之后,我们用下面这三行代码来检查模型正确性、把模型以文本形式输出、存储到一个 ".onnx" 文件里。这里用 onnx.checker.check_model 来检查模型是否满足 ONNX 标准是必要的,因为无论模型是否满足标准,ONNX 都允许我们用 onnx.save 存储模型。我们肯定不希望生成一个不满足标准的模型。
成功执行这些代码的话,程序会以文本格式输出模型的信息,其内容应该和我们在上一节展示的输出一样。
整理一下,用 ONNX Python API 构造模型的代码如下:
老规矩,我们可以用 ONNX Runtime 运行模型,来看看模型是否正确:
一切顺利的话,这段代码不会有任何报错信息。这说明我们的模型等价于执行 a * x + b 这个计算。
读取并修改 ONNX 模型
通过用 API 构造 ONNX 模型,我们已经彻底搞懂了 ONNX 由哪些模块组成。现在,让我们看看该如何读取现有的".onnx"文件并从中提取模型信息。
首先,我们可以用下面的代码读取一个 ONNX 模型:
之前在输出模型时,我们传给 onnx.save 的是一个 ModelProto 的对象。同理,用上面的 onnx.load 读取 ONNX 模型时,我们收获的也是一个 ModelProto 的对象。输出这个对象后,我们应该得到和之前完全相同的输出。 接下来,我们来看看怎么把图 GraphProto、节点 NodeProto、张量信息 ValueInfoProto 读取出来:
使用如上这些代码,我们可以分别访问模型的图、节点、张量信息。这里大家或许会有疑问:该怎样找出 graph.node,graph.input 中 node, input 这些属性名称呢?其实,属性的名称就写在每个对象的输出里。我们以 print(node) 的输出为例:
在这段输出中,我们能看出 node 其实就是一个列表,列表中的对象有属性 input, output, op_type(这里 input 也是一个列表,它包含的两个元素都显示出来了)。我们可以用下面的代码来获取 node 里第一个节点 Mul 的属性:
当我们想知道 ONNX 模型某数据对象有哪些属性时,我们不必去翻 ONNX 文档,只需要先把数据对象输出一下,然后在输出结果找出属性名即可。
读取完 ONNX 模型的信息后,修改 ONNX 模型就是一件很轻松的事了。我们既可以按照上一小节的模型构造方法,新建节点和张量信息,与原有模型组合成一个新的模型,也可以在不违反 ONNX 规范的前提下直接修改某个数据对象的属性。
这里我们来看一个直接修改模型属性的例子:
在读入之前的 linear_func.onnx 模型后,我们可以直接修改第二个节点的类型 node[1].op_type,把加法变成减法。这样,我们的模型描述的是 a * x - b 这个线性函数。大家感兴趣的话,可以用 ONNX Runtime 运行新模型 linear_func_2.onnx,来验证一下它和 a * x - b 是否等价。
调试 ONNX 模型
在实际部署中,如果用深度学习框架导出的 ONNX 模型出了问题,一般要通过修改框架的代码来解决,而不会从 ONNX 入手,我们把 ONNX 模型当成一个不可修改的黑盒看待。 现在,我们已经深入学习了 ONNX 的原理,可以尝试对 ONNX 模型本身进行调试了。在这一节里,让我们看看该如何巧妙利用 ONNX 提供的子模型提取功能,对 ONNX 模型进行调试。
子模型提取
ONNX 官方为开发者提供了子模型提取(extract)的功能。子模型提取,顾名思义,就是从一个给定的 ONNX 模型中,拿出一个子模型。这个子模型的节点集、边集都是原模型中对应集合的子集。让我们来用 PyTorch 导出一个复杂一点的 ONNX 模型,并在它的基础上执行提取操作:
这个模型的可视化结果如下图所示(提取子模型需要输入边的序号,为了大家方面阅读,这幅图标出了之后要用到的边的序号):
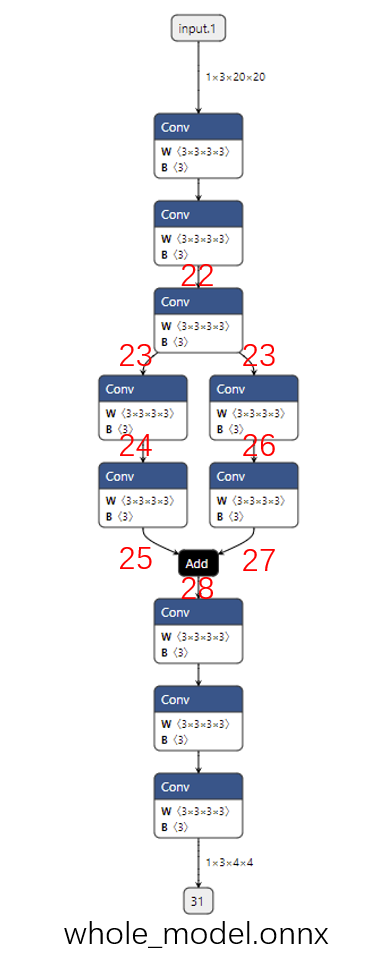
在前面的章节中,我们学过,ONNX 的边用同名张量表示的。也就是说,这里的边序号,实际上是前一个节点的输出张量序号和后一个节点的输入张量序号。由于这个模型是用 PyTorch 导出的,这些张量序号都是 PyTorch 自动生成的。
接着,我们可以下面的代码提取出一个子模型:
子模型的可视化结果如下图所示:
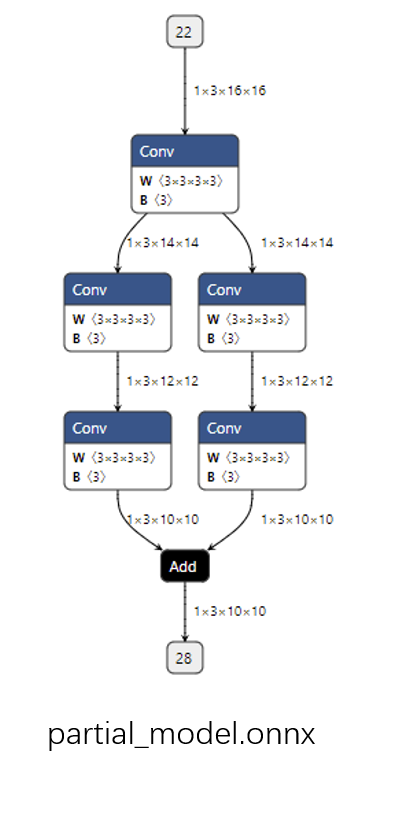
通过观察代码和输出图,应该不难猜出这段代码的作用是把原计算图从边 22 到边 28 的子图提取出来,并组成一个子模型。onnx.utils.extract_model 就是完成子模型提取的函数,它的参数分别是原模型路径、输出模型路径、子模型的输入边(输入张量)、子模型的输出边(输出张量)。
直观地来看,子模型提取就是把输入边到输出边之间的全部节点都取出来。那么,这个功能在使用上有什么限制呢?基于 whole_model.onnx, 我们来看一看三个子模型提取的示例。
添加额外输出
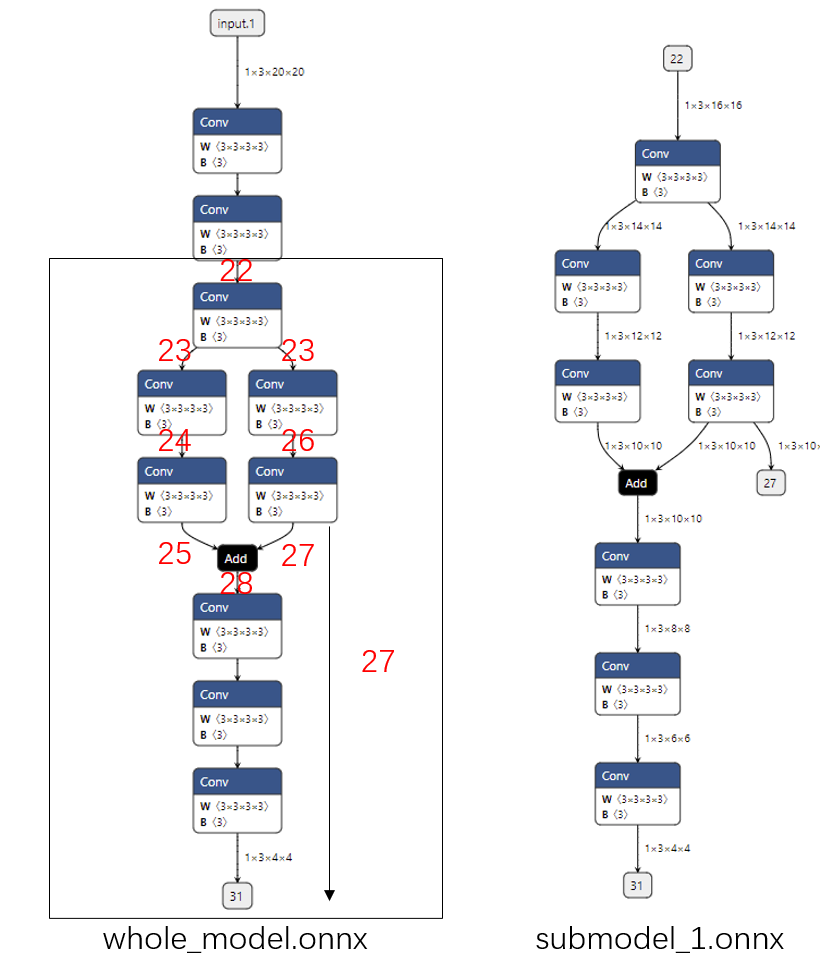
我们在提取时新设定了一个输出张量,如下面的代码所示:
我们可以看到子模型会添加一条把张量输出的新边,如下图所示:
添加冗余输入
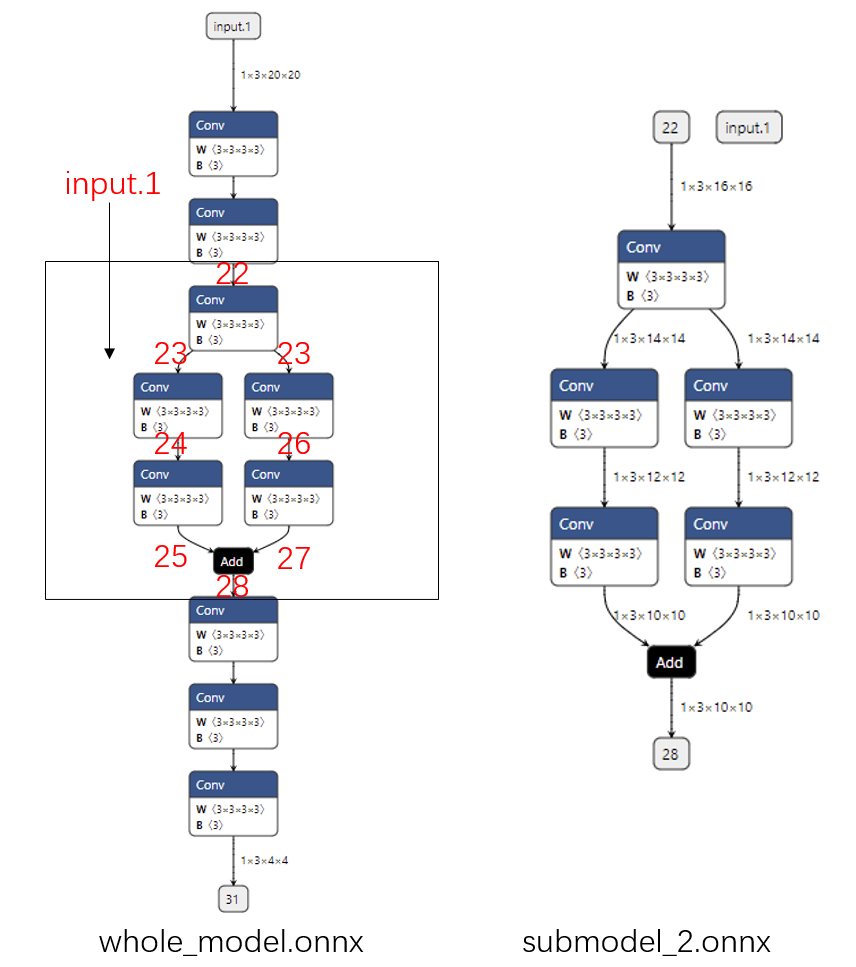
如果我们还是像开始一样提取边 22 到边 28 之间的子模型,但是多添加了一个输入 input.1,那么提取出的子模型会有一个冗余的输入 input.1,如下面的代码所示:
从下图中可以看出:无论给这个输入传入什么值,都不会影响子模型的输出。可以认为如果只用子模型的部分输入就能得到输出,那么那些”较早“的多出来的输入就是冗余的。
输入信息不足
这次,我们尝试提取的子模型输入是边 24,输出是边 28。如下面的代码和图所示:
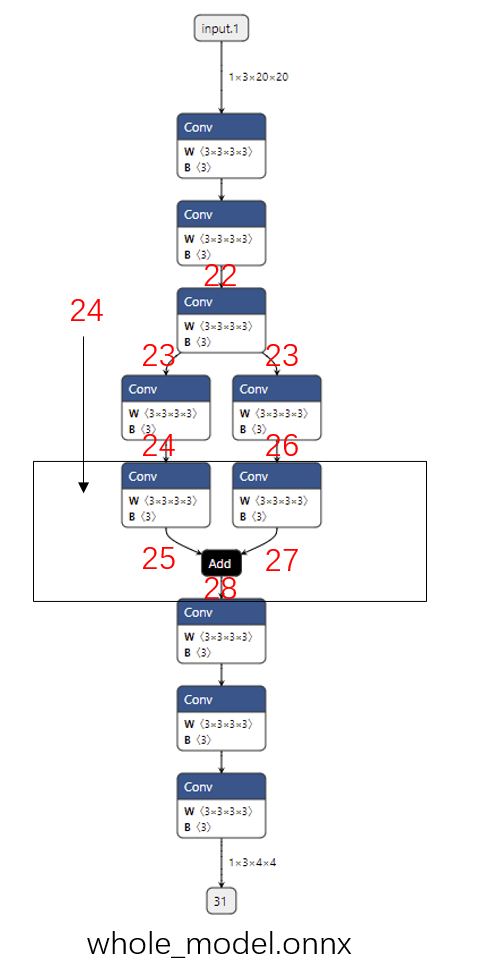
从图中可以看出,想通过边 24 计算边 28 的结果,至少还需要输入边 26,或者更上面的边。仅凭借边 24 是无法计算出边 28 的结果的,因此这样提取子模型会报错。
通过上面几个使用示例,我们可以整理出子模型提取的实现原理:新建一个模型,把给定的输入和输出填入。之后把图的所有有向边反向,从输出边开始遍历节点,碰到输入边则停止,把这样遍历得到的节点做为子模型的节点。
如果还没有彻底弄懂这个提取原理,没关系,我们只要尽量保证在填写子模型的输入输出时,让输出恰好可以由输入决定即可。
输出 ONNX 中间节点的值
在使用 ONNX 模型时,最常见的一个需求是能够用推理引擎输出中间节点的值。这多见于深度学习框架模型和 ONNX 模型的精度对齐中,因为只要能够输出中间节点的值,就能定位到精度出现偏差的算子。我们来看看如何用子模型提取实现这一任务。
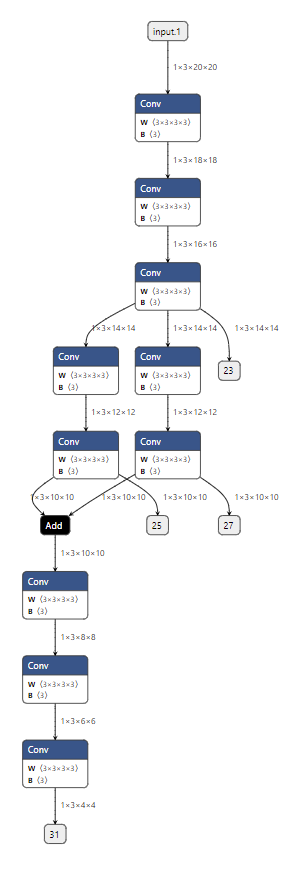
在刚刚的第一个子模型提取示例中,我们添加了一条原来模型中不存在的输出边。用同样的原理,我们可以在保持原有输入输出不变的同时,新增加一些输出,提取出一个能输出中间节点的”子模型“。例如:
在这个子模型中,我们在保持原有的输入 input.1,输出 31 的同时,把其他几个边加入了输出中。如下图所示:
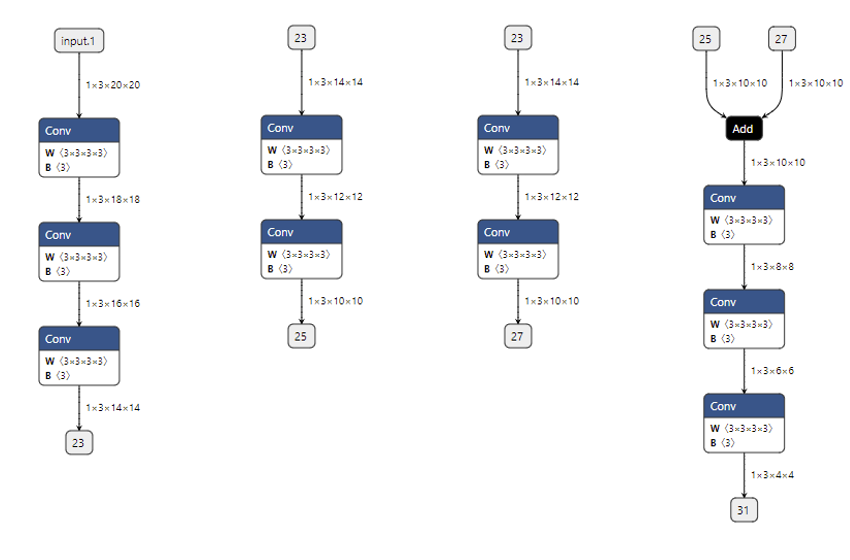
这样,用 ONNX Runtime 运行 more_output_model.onnx 这个模型时,我们就能得到更多的输出了。 为了方便调试,我们还可以把原模型拆分成多个互不相交的子模型。这样,在每次调试时,可以只对原模型的部分子模块调试。比如:
在这个例子中,我们把原来较为复杂的模型拆成了四个较为简单的子模型,如下图所示。在调试时,我们可以先调试顶层的子模型,确认顶层子模型无误后,把它的输出做为后面子模型的输入。
比如对于这些子模型,我们可以先调试第一个子模型,并存储输出 23。之后把张量 23 做为第二个和第三个子模型的输入,调试这两个模型。最后用同样方法调试第四个子模型。可以说,有了子模型提取功能,哪怕是面对一个庞大的模型,我们也能够从中提取出有问题的子模块,细致地只对这个子模块调试。
子模型提取固然是一个便利的 ONNX 调试工具。但是,在实际的情况中,我们一般是用 PyTorch 等框架导出 ONNX 模型。这里有两个问题:
一旦 PyTorch 模型改变,ONNX 模型的边序号也会改变。这样每次提取同样的子模块时都要重新去 ONNX 模型里查序号,如此繁琐的调试方法是不会在实践中采用的。
即使我们能保证 ONNX 的边序号不发生改变,我们也难以把 PyTorch 代码和 ONNX 节点对应起来——当模型结构变得十分复杂时,要识别 ONNX 中每个节点的含义是不可能的。
MMDeploy 为 PyTorch 模型添加了模型分块功能。使用这个功能,我们可以通过只修改 PyTorch 模型的实现代码来把原模型导出成多个互不相交的子 ONNX 模型。我们会在后续教程中对其介绍。
总结
在这篇教程中,我们抛开了 PyTorch,学习了 ONNX 模型本身的知识。老规矩,我们来总结一下这篇教程的知识点:
ONNX 使用 Protobuf 定义规范和序列化模型。
一个 ONNX 模型主要由
ModelProto,GraphProto,NodeProto,ValueInfoProto这几个数据类的对象组成。使用
onnx.helper.make_xxx,我们可以构造 ONNX 模型的数据对象。onnx.save()可以保存模型,onnx.load()可以读取模型,onnx.checker.check_model()可以检查模型是否符合规范。onnx.utils.extract_model()可以从原模型中取出部分节点,和新定义的输入、输出边构成一个新的子模型。利用子模型提取功能,我们可以输出原 ONNX 模型的中间结果,实现对 ONNX 模型的调试。
至此,我们对 ONNX 相关知识的学习就告一段落了。回顾一下,我们先学习了 PyTorch 转 ONNX 有关 API 的用法;接着,我们学习了如何用自定义算子解决 PyTorch 和 ONNX 表达能力不足的问题;最后我们单独学习了 ONNX 模型的调试方法。通过对 ONNX 由浅入深的学习,我们基本可以应对模型部署中和 ONNX 有关的绝大多数问题了。
如果大家想了解更多有关 ONNX API 的知识,可以去阅读 ONNX 的官方 Python API 文档。
Last updated