
🌲右值引用|移动语义|完美转发|C++11
右值引用和移动语义
作用:C++11中引用了右值引用和移动语义,可以避免无谓的复制,提高了程序性能。
左值是表达式结束后仍然存在的持久对象,右值是指表达式结束时就不存在的临时对象。
区分左值和右值的便捷方法是看能不能对表达式取地址,如果能则为左值,否则为右值;
将亡值是C++11新增的、与右值引用相关的表达式,比如:将要被移动的对象、T&&函数返回的值、std::move返回值和转换成T&&的类型的转换函数返回值。
C++11中的所有的值必将属于左值、将亡值、纯右值三者之一,将亡值和纯右值都属于右值。 区分表达式的左右值属性:如果可对表达式用&符取址,则为左值,否则为右值。
左值 lvalue 是有标识符、可以取地址的表达式,最常见的情况有:
变量、函数或数据成员的名字
返回左值引用的表达式,如 ++x、x = 1、cout << ' '
字符串字面量如 "hello world"
纯右值 prvalue 是没有标识符、不可以取地址的表达式,一般也称之为“临时对象”。最常见的情况有:
返回非引用类型的表达式,如 x++、x + 1、make_shared(42)
除字符串字面量之外的字面量,如 42、true
&&的特性
&&的特性右值引用就是对一个右值进行引用的类型。因为右值没有名字,所以我们只能通过引用的方式找到它。 无论声明左值引用还是右值引用都必须立即进行初始化,因为引用类型本身并不拥有所把绑定对象的内存,只是该对象的一个别名。
通过右值引用的声明,该右值又“重获新生”,其生命周期其生命周期与右值引用类型变量的生命周期一 样,只要该变量还活着,该右值临时量将会一直存活下去。
在C++中,并不是所有情况下 && 都代表是一个右值引用,具体的场景体现在模板和自动类型推导中,如果是模板参数需要指定为T&&,如果是自动类型推导需要指定为auto &&,在这两种场景下 &&被称作未定的引用类型。另外还有一点需要额外注意const T&&表示一个右值引用,不是未定引用类型。
先来看第一个例子,在函数模板中使用&&:
在上面的例子中函数模板进行了自动类型推导,需要通过传入的实参来确定参数param的实际类型。
第4行中,对于
f(10)来说传入的实参10是右值,因此T&&表示右值引用第6行中,对于
f(x)来说传入的实参是x是左值,因此T&&表示左值引用第7行中,
f1(x)的参数是const T&&不是未定引用类型,不需要推导,本身就表示一个右值引用
再来看第二个例子:
第4行中
auto&&表示一个整形的左值引用第5行中
auto&&表示一个整形的右值引用第6行中
decltype(x)&&等价于int&&是一个右值引用不是未定引用类型,y是一个左值,不能使用左值初始化一个右值引用类型。
由于上述代码中存在T&&或者auto&&这种未定引用类型,当它作为参数时,有可能被一个右值引用初始化,也有可能被一个左值引用初始化,在进行类型推导时右值引用类型(&&)会发生变化,这种变化被称为引用折叠。在C++11中引用折叠的规则如下:
通过右值推导
T&&或者auto&&得到的是一个右值引用类型通过非右值(右值引用、左值、左值引用、常量右值引用、常量左值引用)推导
T&&或者auto&&得到的是一个左值引用类型
第2行:
a1为右值引用,推导出的bb为左值引用类型第3行:
5为右值,推导出的bb1为右值引用类型第7行:
a3为左值引用,推导出的cc为左值引用类型第8行:
a2为左值,推导出的cc1为左值引用类型第12行:
s1为常量左值引用,推导出的dd为常量左值引用类型第13行:
s2为常量右值引用,推导出的ee为常量左值引用类型第15行:
x为右值引用,不需要推导,只能通过右值初始化
再看最后一个例子,代码如下:
测试代码输出的结果如下:
根据测试代码可以得知,编译器会根据传入的参数的类型(左值还是右值)调用对应的重置函数(printValue),函数forward()接收的是一个右值,但是在这个函数中调用函数printValue()时,参数k变成了一个命名对象,编译器会将其当做左值来处理。
在C++中,右值引用是用来绑定右值的,但一旦右值引用有了名字,它就变成了一个左值。这就是为什么在forward(int&& k)函数中,虽然k是一个右值引用,但在函数内部,k是一个命名对象,因此它被视为左值。
看下面这张图可能更容易理解:

图片来源:https://blog.csdn.net/ChaoFreeandeasy_/article/details/130229252?spm=1001.2014.3001.5501
&& 的总结如下:
左值和右值是独立于它们的类型的,右值引用类型可能是左值也可能是右值。
auto&&或函数参数类型自动推导的T&&是一个未定的引用类型,被称为universal references, 它可能是左值引用也可能是右值引用类型,取决于初始化的值类型。所有的右值引用叠加到右值引用上仍然是一个右值引用,其他引用折叠都为左值引 用。当 T&& 为 模板参数时,输入左值,它会变成左值引用,而输入右值时则变为具名的右值引用。
编译器会将已命名的右值引用视为左值,而将未命名的右值引用视为右值。
右值引用优化性能,避免深拷贝
对于含有堆内存的类,我们需要提供深拷贝的拷贝构造函数,如果使用默认构造函数,会导致堆内存的重复删除,比如下面的代码:
在上面的代码中,默认构造函数是浅拷贝,main函数的 a 和Get函数的 b 会指向同一个指针 m_ptr,在 析构的时候会导致重复删除该指针。
两个的区别:在未定义显示拷贝构造函数的情况下,系统会调用默认的拷贝函数--即浅拷贝,它能够完成成员的一一复制。
当数据成员中没有指针时,浅拷贝是可行的;但当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址,当对象快 结束时,会调用两次析构函数,而导致指针悬挂现象,所以,此时,必须采用深拷贝。
深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据,从而也就解决了指针悬挂的问题。简而言之,当数据 成员中有指针时,必须要用深拷贝。
正确的做法是提供深拷贝的拷贝构造函数,比如下面的代码(关闭 返回值优化的情况下):
这样就可以保证拷贝构造时的安全性,但有时这种拷贝构造却是不必要的,比如上面代码中的拷贝构造 就是不必要的。上面代码中的 Get 函数会返回临时变量,然后通过这个临时变量拷贝构造了一个新的对象 b,临时变量在拷贝构造完成之后就销毁了,如果堆内存很大,那么,这个拷贝构造的代价会很大, 带来了额外的性能损耗。有没有办法避免临时对象的拷贝构造呢?答案是肯定的。看下面的代码:
上面的代码中没有了拷贝构造,取而代之的是移动构造( Move Construct)。从移动构造函数的实现 中可以看到,它的参数是一个右值引用类型的参数 A&&,这里没有深拷贝,只有浅拷贝,这样就避免了对临时对象的深拷贝,提高了性能。这里的A&& 用来根据参数是左值还是右值来建立分支,如果是临时 值,则会选择移动构造函数。移动构造函数只是将临时对象的资源做了浅拷贝,不需要对其进行深拷贝,从而避免了额外的拷贝,提高性能。这也就是所谓的移动语义( move 语义),右值引用的一个重要目的是用来支持移动语义的。
移动语义可以将资源(堆、系统对象等)通过浅拷贝方式从一个对象转移到另一个对象,这样能够减少不必要的临时对象的创建、拷贝以及销毁,可以大幅度提高 C++ 应用程序的性能,消除临时对象的维护 (创建和销毁)对性能的影响。
以一个简单的 string 类为示例,实现拷贝构造函数和拷贝赋值操作符。
实现了调用拷贝构造函数的操作和拷贝赋值操作符的操作。MyString(“Hello”) 和 MyString(“World”) 都是临时对象,也就是右值。虽然它们是临时的,但程序仍然调用了拷贝构造和拷贝赋值,造成了没有意义的资源申请和释放的操作。如果能够直接使用临时对象已经申请的资源,既能节省资源,又能节省资源申请和释放的时间,这正是定义转移语义的目的。
用c++11的右值引用来定义这两个函数
有了右值引用和转移语义,我们在设计和实现类时,对于需要动态申请大量资源的类,应该设计右值引用的拷贝构造函数和赋值函数,以提高应用程序的效率。
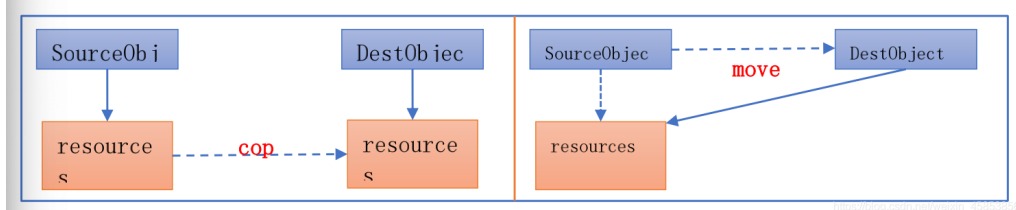
移动(move )语义
我们知道移动语义是通过右值引用来匹配临时值的,那么,普通的左值是否也能借助移动语义来优化性 能呢?C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语义。std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转义,没有内存拷贝。
forward 完美转发
右值引用类型是独立于值的,一个右值引用作为函数参数的形参时,在函数内部转发该参数给内部其他函数时,它就变成一个左值,并不是原来的类型了。如果需要按照参数原来的类型转发到另一个函数,可以使用C++11提供的std::forward()函数,该函数实现的功能称之为完美转发。
当T为左值引用类型时,t将被转换为T类型的左值当T不是左值引用类型时,t将被转换为T类型的右值
下面通过一个例子演示一下关于std::forward()的使用:
测试代码打印的结果如下:
testForward(520);函数的形参为未定引用类型T&&,实参为右值,初始化后被推导为一个右值引用printValue(v);已命名的右值v,编译器会视为左值处理,实参为左值printValue(move(v));已命名的右值编译器会视为左值处理,通过move又将其转换为右值,实参为右值printValue(forward<T>(v));forward的模板参数为右值引用,最终得到一个右值,实参为``右值`
testForward(num);函数的形参为未定引用类型T&&,实参为左值,初始化后被推导为一个左值引用printValue(v);实参为左值printValue(move(v));通过move将左值转换为右值,实参为右值printValue(forward<T>(v));forward的模板参数为左值引用,最终得到一个左值引用,实参为左值
testForward(forward<int>(num));forward的模板类型为int,最终会得到一个右值,函数的形参为未定引用类型T&&被右值初始化后得到一个右值引用类型printValue(v);已命名的右值v,编译器会视为左值处理,实参为左值printValue(move(v));已命名的右值编译器会视为左值处理,通过move又将其转换为右值,实参为右值printValue(forward<T>(v));forward的模板参数为右值引用,最终得到一个右值,实参为右值
testForward(forward<int&>(num));forward的模板类型为int&,最终会得到一个左值,函数的形参为未定引用类型T&&被左值初始化后得到一个左值引用类型printValue(v);实参为左值printValue(move(v));通过move将左值转换为右值,实参为右值printValue(forward<T>(v));forward的模板参数为左值引用,最终得到一个左值,实参为左值
testForward(forward<int&&>(num));forward的模板类型为int&&,最终会得到一个右值,函数的形参为未定引用类型T&&被右值初始化后得到一个右值引用类型printValue(v);已命名的右值v,编译器会视为左值处理,实参为左值printValue(move(v));已命名的右值编译器会视为左值处理,通过move又将其转换为右值,实参为右值printValue(forward<T>(v));forward的模板参数为右值引用,最终得到一个右值,实参为右值
综合示例
reference
Last updated